Overview
Markov decision processes (MDPs) are a formalism for fully observable, sequential complex decision problems where an agent engages in an extended interaction with the environment. In other words, an MDP is a reinforcement learning task that satisfies the Markov property.
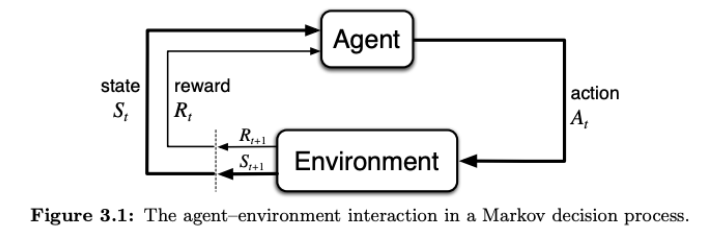
A Markov decision process has the following data: a state space ; an action space ; a transition function for how actions in states lead to new states; a reward function which has a value corresponding to each transition; and a discount rate .
For a given MDP, a policy represents the behavior of a decision-maker by specifying what actions will be taken at each state 1.
Related notes:
- (Sequential) decision problems
- State and action value functions
- Policy prediction and control
- Bandit problems
- Temporal difference learning
Decision policies in MDPs
Primary note: Action selection in decision problems
Decision policy
Given a Markov decision process , a policy is a mapping where is the probability of taking action when in state . For example, a deterministic policy is a mapping , while a stochastic policy maps states to action distributions .
Trajectory of a MDP, return
Given a Markov decision process with reward function and transition function , a single trajectory is a sequence of states, actions, and rewards
where the reward is defined over a state/action/next-state tuple. The return associated with the trajectory is the discounted cumulative reward
State reward function
In some cases, such as in the literature on successor representation, the state reward function associated with following policy is denoted , where is precisely the expected immediate reward received when in state and taking actions with probability .
The expression for depends on the form of the reward function, as well as whether the policy is deterministic or stochastic:
| Reward function form | Deterministic policy | Stochastic policy |
|---|---|---|
Variations
| Single agent | Multi-agent | |
|---|---|---|
| Fully observable | Markov decision process (MDP) | Stochastic game |
| Partially observable | Partially observable Markov decision process (POMDP) | Partially observable stochastic game? |
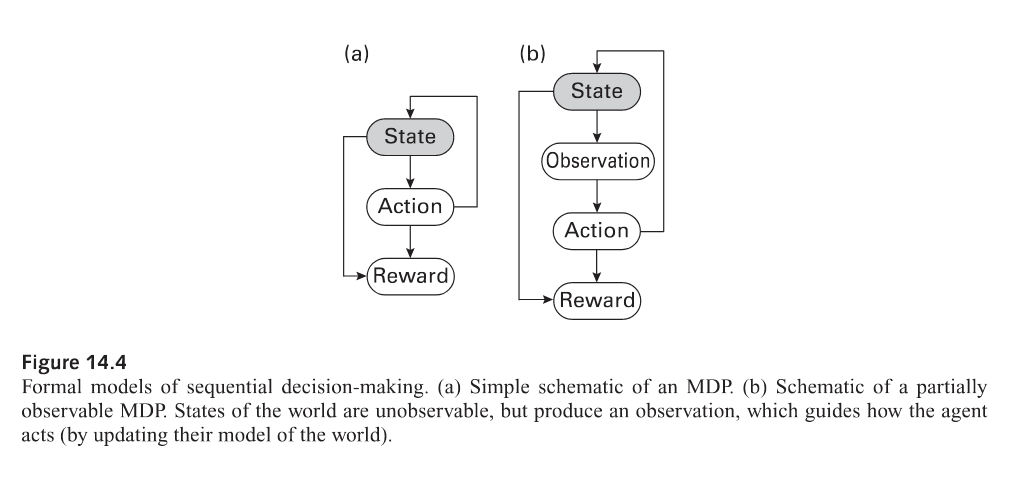
Partially observable MDPs

Multi-agent MDPs with sub-tasks

Meta-level MDP
wip @2024griffithsBayesian 331
Code snippets
(\mathcal S, \mathcal A, T, R, \gamma)
Notes
- @2024griffithsBayesian policy iteration? p. 208
- The MDP framework with differs from a full reinforcement learning setting in that, in the MDP framework, we have general access to the underlying transition probabilities and reward function, and we can examine any state at any time with dynamic programming instead of sampling in sequence. Specifically, in the MDP framework, rewards are given while values are computed or learned; in contrast, the reinforcement learning problem involves trying to find the optimal policy for an MDP in the absence of information about how actions modify states, or what costs or rewards result from an action.
Footnotes
-
In the language of more general sequential decision problems (i.e., in @2025icardResource), this is also known as a stationary strategy, a map from histories to action distributions that depends only on the current state. ↩