Overview
Markov decision processes (MDPs) are a formalism for fully observable, sequential complex decision problems where an agent engages in an extended interaction with the environment.
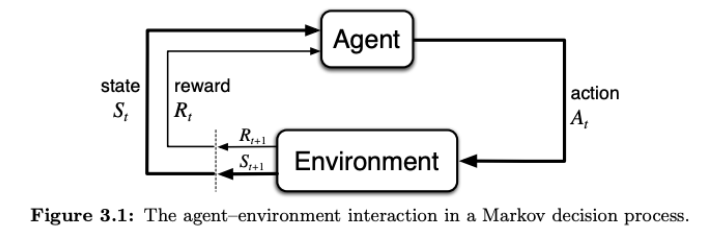
A Markov decision process has the following data: a state space ; an action space ; a transition function for how actions in states lead to new states; a reward function which has a value corresponding to each transition; and a discount rate .
For a given MDP, a policy represents the behavior of a decision-maker by specifying what actions will be taken at each state. Policy prediction or evaluation involves calculating the expected return from a fixed policy, while policy control involves selecting the optimal policy based on the highest expected reward.
Related notes:
Key terms
- Policy: a formalization of agent behavior as a function mapping states to actions.
- Prediction: also known as policy evaluation; the computational problem of determining how much long-term reward would be obtained given a policy and an initial state.
- Value: a standard method of defining long-term reward as the expected cumulative discounted infinite sum of rewards. In contrast to reward, value is derived from a combination of rewards, the environment, and future behaviors.
- Optimal control: also known as policy optimization; the computational problem of finding the policy with the maximal value function given an MDP. Using the standard definition of value above, there is a unique optimal value function expressed in terms of Bellman optimality equations.
- Planning: the control problem with a known reward and transition model.
- Dynamic programming: in this context, a class of algorithms that, given the full state space, calculates the value function via backward induction. wip
- Value iteration: the dynamic programming algorithm for optimal control.
Policies and value functions
Decision policy, value
Given a Markov decision process , a policy represents the behavior of a decision-maker by specifying what actions will be taken at each state. For example, a deterministic policy is a mapping , while a stochastic policy maps states to action distributions .
The value of a policy from a state is the expected cumulative, discounted reward that results from following .
Trajectory of a MDP, return
Given a Markov decision process with reward function and transition function , a single trajectory is a sequence of states, actions, and rewards
where the reward is defined over a state/action/next-state tuple. The return associated with the trajectory is the discounted cumulative reward
Policy prediction
The policy prediction problem is to calculate the state value function, or expected return, from every state that results from following a fixed policy .
Equation: State value
The value of a state under policy is given by the expected return (i.e., cumulative discounted reward) conditioned on starting at state and following thereafter:
where is the reward at with action given by the policy and next state given by transition dynamics , and is the discount rate.
The Monte Carlo policy prediction algorithm calculates by repeatedly sampling trajectories and averaging returns.
Algorithm: Monte Carlo policy prediction
Input: A policy to evaluate and a state to evaluate from.
- Initialize the return and timestep
- While is not an absorbing state (a state that always leads to itself regardless of what action is taken, and always returns a reward of ):
- Sample action
- Sample next state
- Calculate reward
- Update
- Update
- Return
On the other hand, discounted infinite horizon MDPs have the property that can be expressed with a set of primitive recursive equations. This allows for calculating calculating exact values using dynamic programming: the general idea is to initialize the value function arbitrarily, then use the right-hand expression to calculate updated value functions until the function stops changing and Bellman’s equations are satisfied.
Equation: Bellman’s equation
Algorithm: Bellman policy prediction
Input: A policy , a MDP , and a convergence precision .
- Initialize for all
- For in :
- For :
- If is an absorbing state:
- Skip
- If :
- Break
- Return
Policy control
Policy control is the problem of calculating the optimal policy, which can again be computed recursively. Rather than selecting an action according to a policy , the Bellman optimality equations express selecting the best action in terms of state values. Like before, we have an iterative algorithm that converges on a satisfying these equations.
Equation: Bellman optimality equations
Algorithm: Value iteration
Input: An MDP and a convergence precision .
- Initialize for all .
- For in :
- For :
- If is absorbing:
- Skip
- If :
- Break
- Return
Given , the optimal policy can be calculated by calculating the optimal state action values for each action in a state, then taking the best action(s). In particular, we have the -value (for “quality”) of an action taken at a state assuming that we will act optimally from then on.
Equation: -value
The optimal stochastic policy is then any policy that is greedy with respect to the optimal -values, meaning it is uniform over all actions equal to the maximum value 1:
where if is true and otherwise, thus normalizes to a probability distribution.
Variations
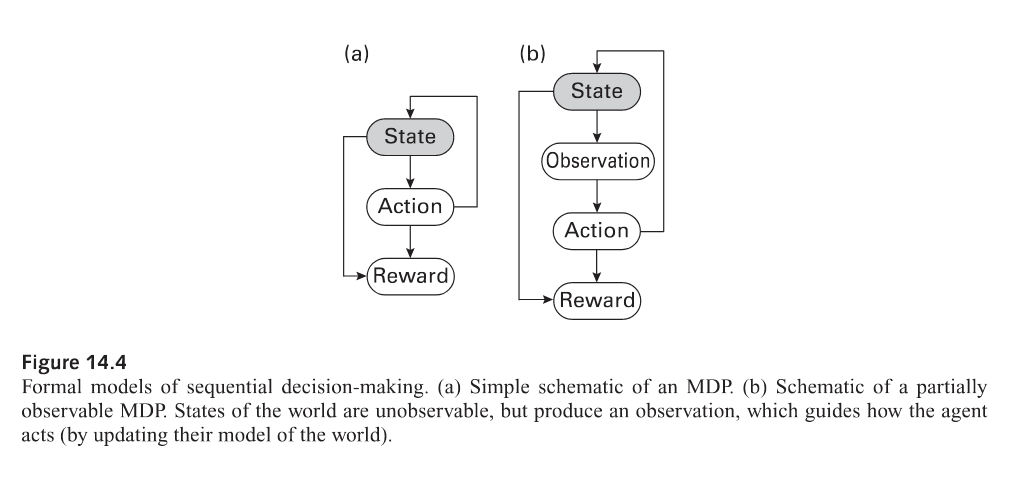
Partially observable MDPs
Stochastic games

Multi-agent MDPs

Multi-agent MDPs with sub-tasks

Meta-level MDP
wip @2024griffithsBayesian 331
Code snippets
(\mathcal S, \mathcal A, T, R, \gamma)
Notes
- @2024griffithsBayesian policy iteration? p. 208
- The MDP framework with differs from a full reinforcement learning setting in that, in the MDP framework, we have general access to the underlying transition probabilities and reward function, and we can examine any state at any time with dynamic programming instead of sampling in sequence. Specifically, in the MDP framework, rewards are given while values are computed or learned; in contrast, the reinforcement learning problem involves trying to find the optimal policy for an MDP in the absence of information about how actions modify states, or what costs or rewards result from an action.
Footnotes
-
For example, if there is only one maximum value, then the policy is deterministic. ↩